Product backlogs as a navigation system for teams and AI agents
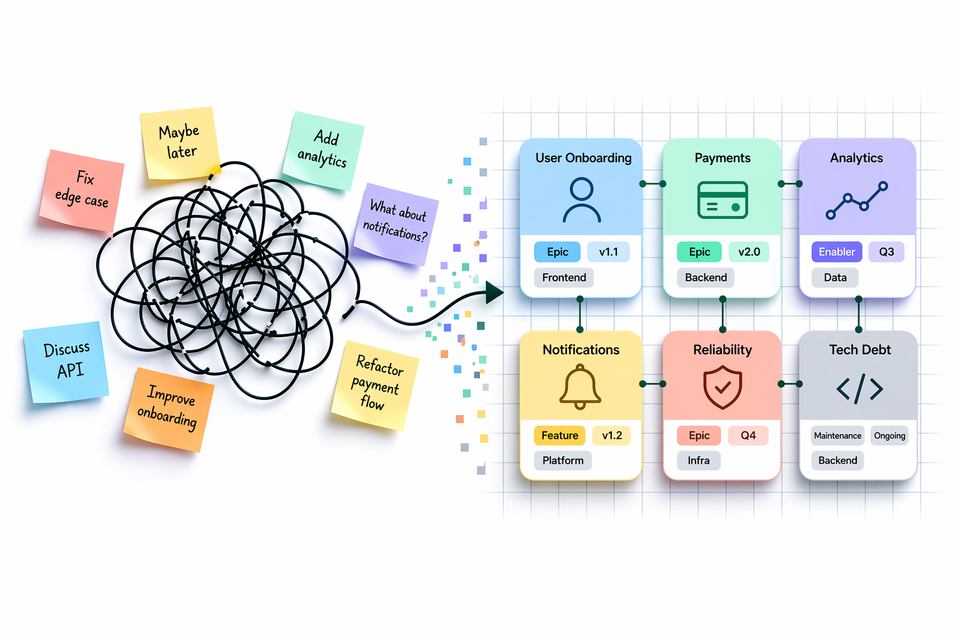
How long does it take for a new joiner to understand what’s going on in your product?
And how easy is it for you to understand what your team - and your AI agents - are actually doing?
Not just at a high level, but concretely:
- “What the team is working on”
- “Why do those things matter”
- “How everything fits together”
In many teams, it takes longer than it should.
Even with a backlog in place, the same questions keep coming up: what’s our progress on this feature? Why are we doing this? Is this related to something else? Has this part of the feature been released? What’s the scope of the next release?
You end up navigating between tickets, epics, and documents to find answers. The information exists, but it’s not structured in a way that makes it easy to understand.
At that point, the backlog stops being a tool and becomes a source of friction.
With today’s tools — including generative AI — it has become easier than ever to produce backlog items, break down features, and generate tasks. But that makes this issue more visible: the volume of work increases, while the structure behind it often doesn’t.
I’ve seen this pattern in different teams. The issue is not the tools or the tickets — it’s the lack of structure behind them.
tl;dr
Most teams treat their backlog as a task list. That's the wrong mental model.
A backlog is the closest thing a product team has to a shared understanding of what they're building and why. When it's well structured, it's a navigation system for engineers, PMs, stakeholders, and increasingly, for AI agents acting on your behalf. When it's not, it's just noise that compounds over time.
The fix isn't better tickets. It's treating the backlog as a system with five dimensions:
- The work (What)
- The context (Why)
- The position in the architecture (Where)
- The type of activity (How)
- And the timing (When)
Each dimension answers a different question. Together, they make the product legible.
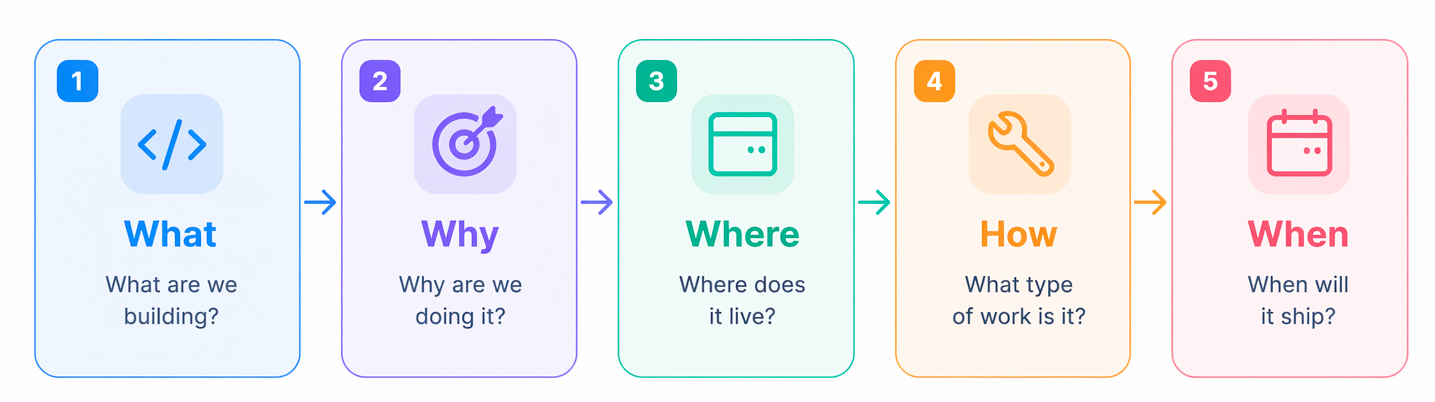
If your backlog can't answer "where are we on this feature" in under 30 seconds, it's not structured, it's just stored.
The problem is not writing tickets
Today, defining backlog items is not the hard part anymore.
With AI tools, it is easy to generate user stories, break down features, or create technical tasks. Producing backlog content is no longer a bottleneck.
But this creates a different problem. The backlog grows faster than our ability to structure and understand it.
You can have well-written tickets and still end up with a backlog that doesn’t work. Because the issue is not the quality of individual items, but how they are organized together.
A backlog should not be a list, but a map
A backlog is often treated as a list of tasks, but in practice, it behaves more like a system. It is where teams understand what needs to be done, why it matters, and how everything connects.
It also acts as a map that helps teams navigate the product and its evolution (what has been done so far, what’s going on right now, and what’s considered for the future)
When the structure is clear, the backlog helps teams move faster and stay aligned. When it is not, it becomes a source of confusion.
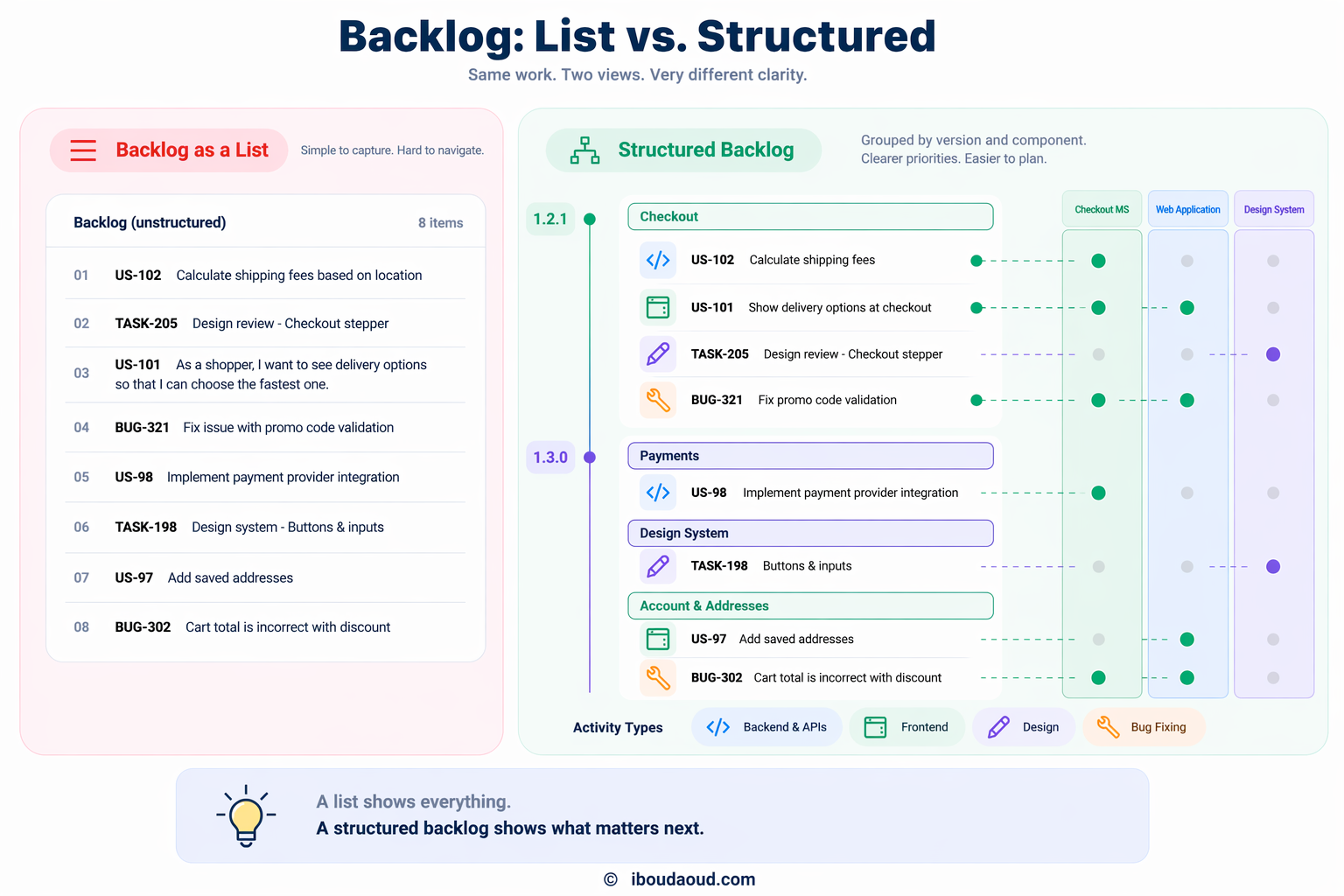
To make that structure explicit, it helps to look at backlog items through a simple model that we’ll call the 5 Dimensions model.
The 5 Dimensions model
Over time, I found it useful to think of backlog items not just as tasks, but as elements structured across a few key dimensions that answer those five questions:
- What is the work?
- Why are we doing it, and what’s the big picture behind it?
- Where is it positioned in the product architecture?
- What kind of work is it?
- When will it be delivered?
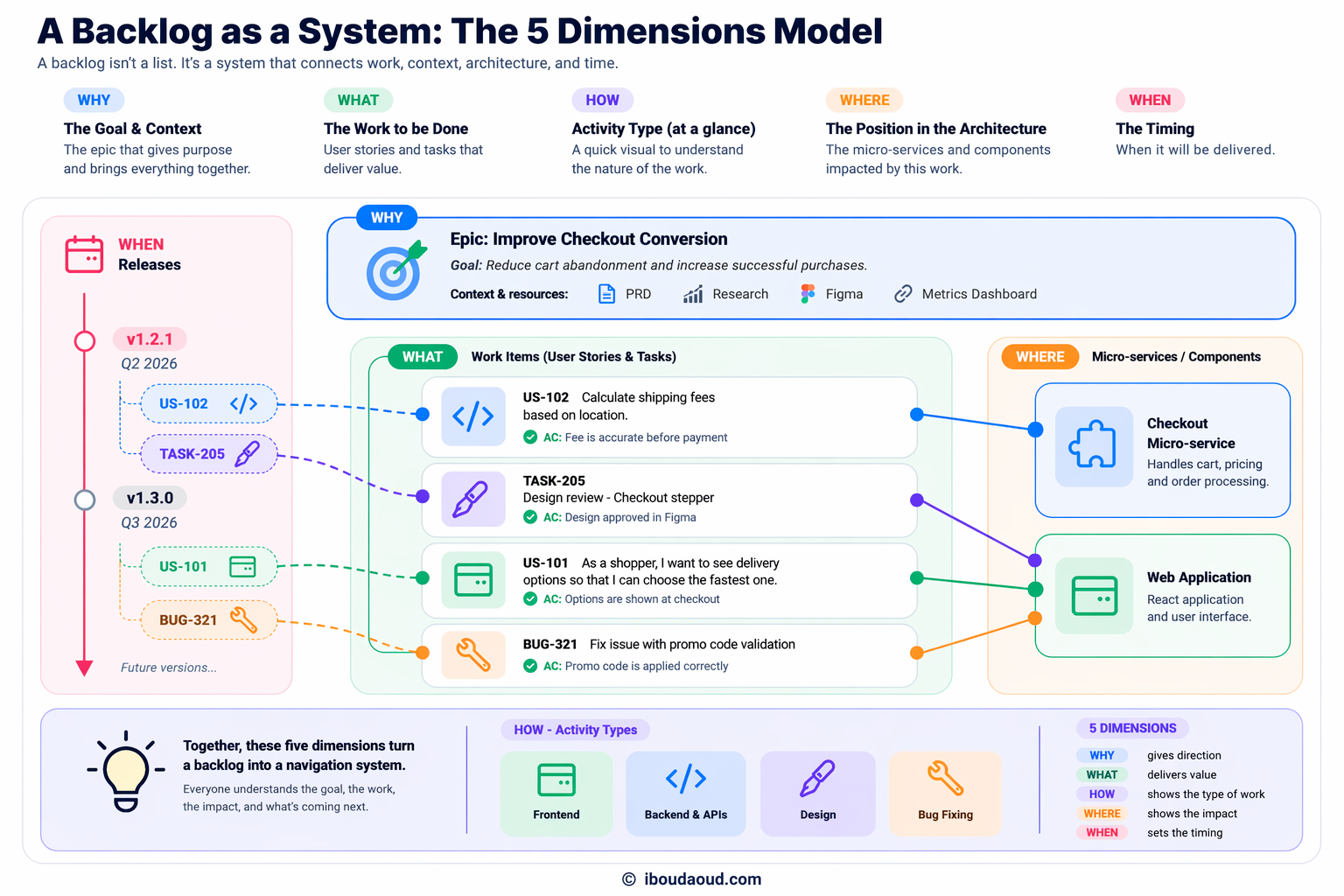
This structure not only removes ambiguity but also gives teams what they need to navigate the product.
For example, the “why” will help teams understand the big picture, find all the artefacts related to a specific goal or feature, identify all the related work, and have a good idea about the overall progress about a specific feature.
On the other hand, the “when” will help teams understand the different increments of each feature, what’s the exact scope of a specific release, and how a release is distributed across product components with the help of the “Where” dimension.
And so on …
We call them dimensions because they are not meant to be written in each ticket. They are distributed across the backlog and linked together to form a coherent system.
Let’s now deep-dive into each one of those 5 dimensions
1. What ...The work to be done
This is the most well-known element in a backlog: the task. It is basically a description of the work to be performed. It usually covers:
- The concerned persona
- The expected outcome
- The acceptance criteria, or how we know that this work is done
If this is unclear, everything else becomes harder: estimation, implementation, testing.
Usually, this will be expressed through the 3C’s framework: "As a [type of user], I want [an action] so that [a benefit/value].
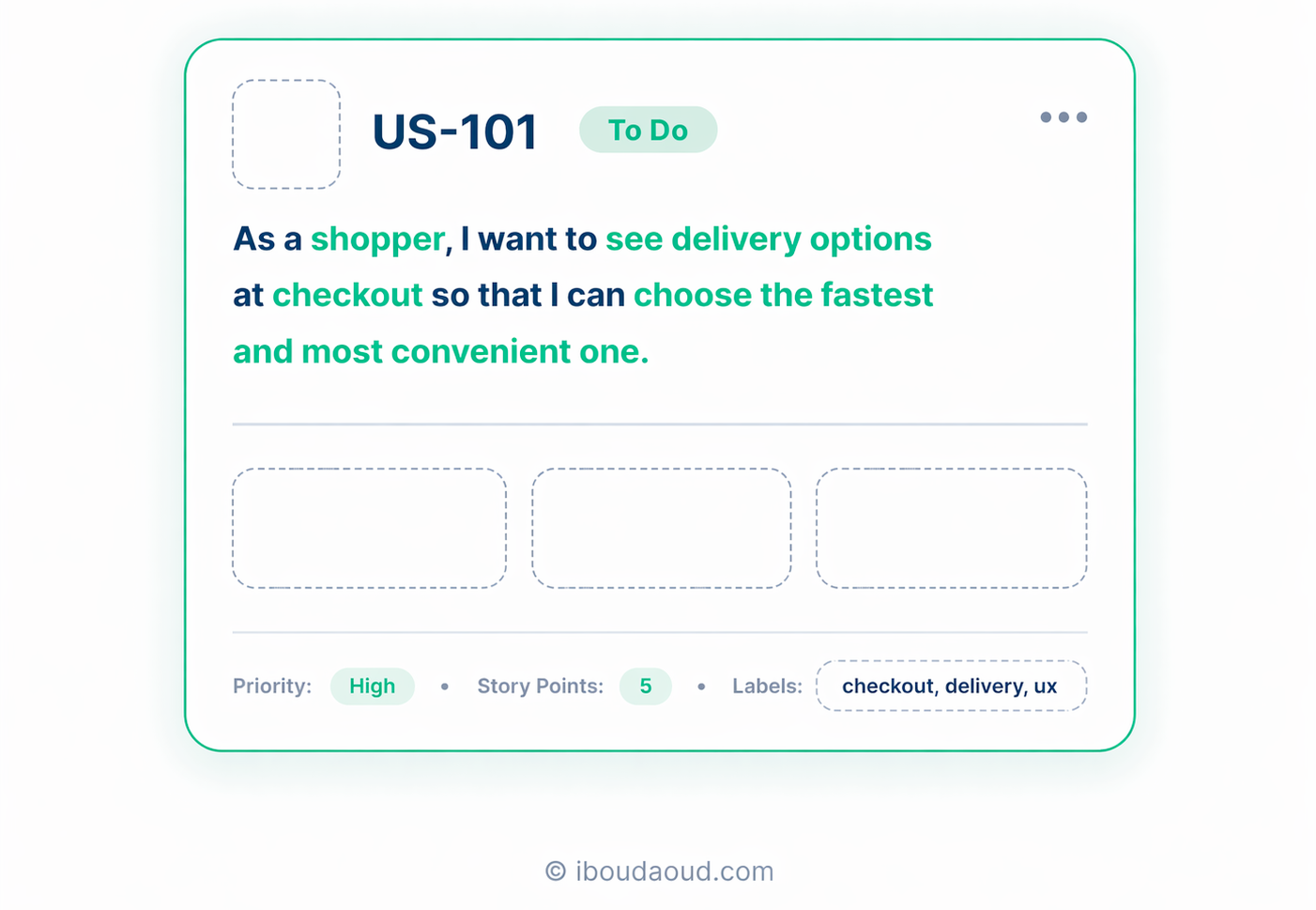
2. Why ... The context and the big picture
The second element is the context of the work to be done and the why behind it. This is achieved through Epics, which are a very common concept in product management.
An epic is mainly a goal that we are trying to achieve in the product. It can be a feature that provides value to end users (Ex: Checkout flow, …) or an enabler for the product and its capabilities (Ex: RGPD compliance)
In epics, we’ll usually find :
- The goal to be achieved
- The context and the storytelling behind it
- All the resources and artefacts related to the epic’s scope
- All the work related to the goal covered by the epic
"Why am I creating this new API endpoint? ", "Why are we adding these new tracking events?", "Is this task related to the task XXX?" are some of the questions that would be avoided when epics are well defined and linked to user stories.
Someone who looks at the epic should have all the answers regarding this specific feature or goal.

Among the common mistakes I noticed product teams committing, is to create epics as just buckets of tasks without clear goals or timelines, and also to not take the time to reference all the necessary materials related to the epic.
A good epic :
- Should have a clear goal
- Should have a timeline and an end date. An epic isn't intended to be open forever (except for some exceptions)
- Should reference all the resources related to the epic (Design, link to API documentation, link to external resources, etc)
- Should be linked to all the tasks involved in its scope
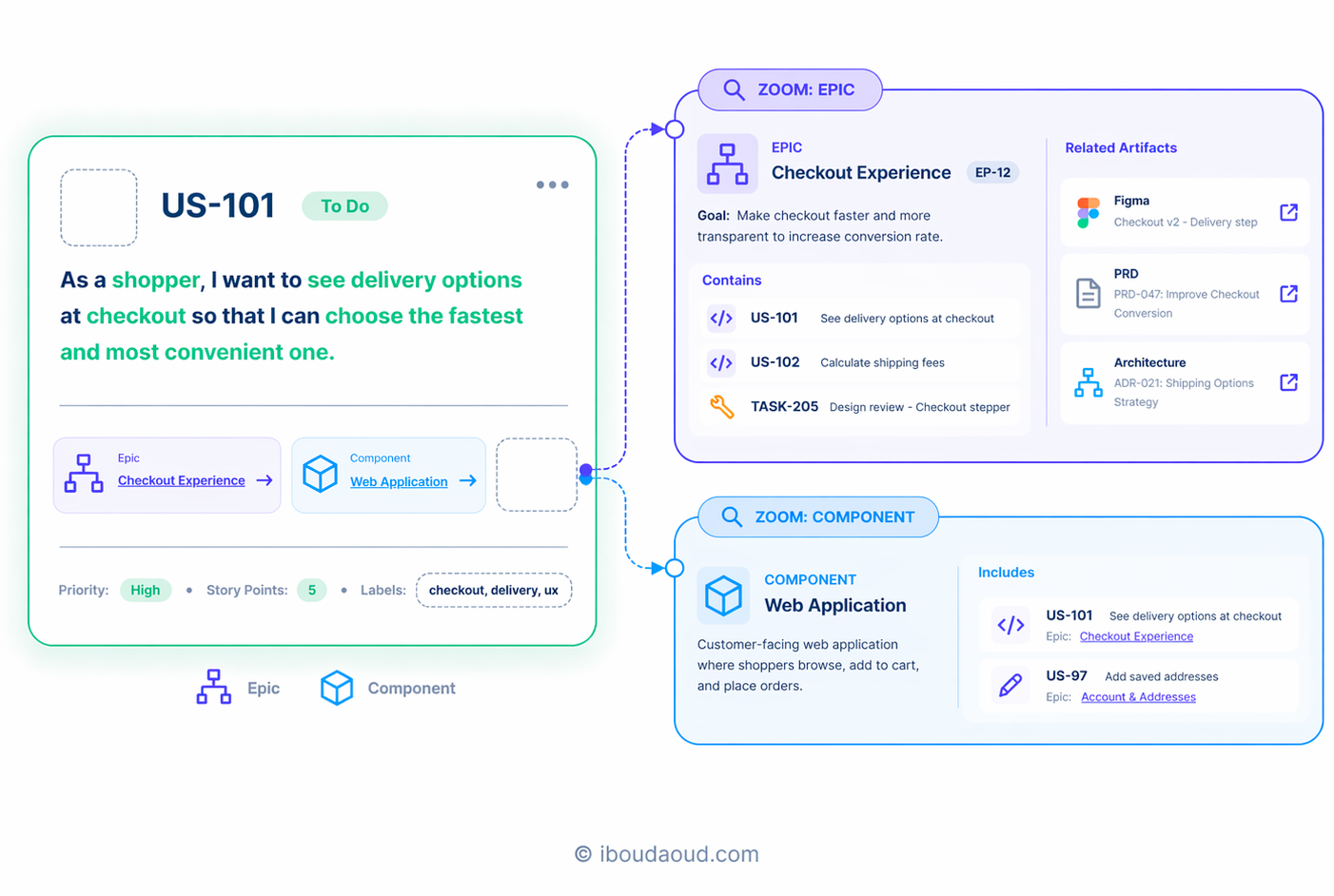
3. Where ... The position in the system
Once the task is defined and the context clarified, it's important to position the work to be done in the product architecture.
- Which part of the product is impacted?
- Which layer of the architecture is concerned?
This can be achieved through components or domains.
Components are a good way to model the product architecture and make it available at the backlog level. In general, components will have a direct mapping to the product architecture.
For example, let's assume we have a mobile application with the following architecture :
- An Android application
- An iOS Application
- A middleware
In that case, we can define at least 3 components: Android-app, iOS-app and middleware.
Why does this matter?
- It clarifies ownership
- It helps assess impact
- It improves coordination across teams
The component's granularity depends on the level of contextualization needed, the architecture complexity, and the team size. Let's imagine, for example, that instead of a simple middleware, you have 20 micro-services that are managed by 5 team members. In this situation, it could be more suitable to create one component for each microservice for better organization.
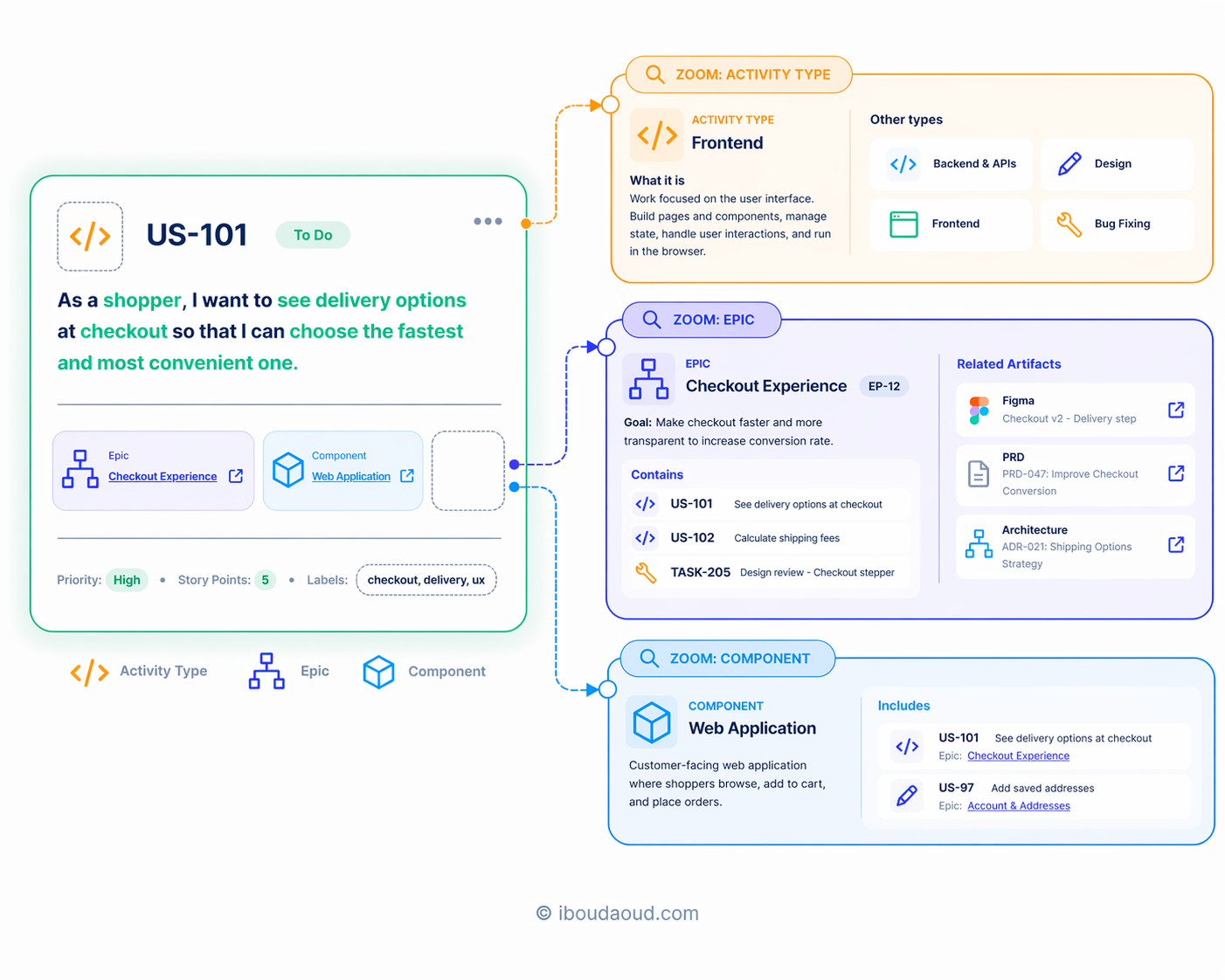
4. How ... The nature of the work
Not all work is the same, even within the same feature.
Delivering a feature often involves different types of activities:
- Design
- Technical design
- Implementation
- bug fixing
- Devops
- …
When everything is mixed:
- Progress becomes harder to track
- Planning becomes less accurate
- Bottlenecks are harder to identify
That’s why it’s important to clearly assign a clear activity type to each task
5. When ... The release or the version
The last dimension is time.
This is what turns the backlog into a clear roadmap.
The idea here isn’t necessarily to assign a shipping date for each item you create, but to organize work into incremental releases.
Each release has :
- A target date
- A real release date
- A clear scope, which is the list of all items related to this increment
When this dimension is added, it helps teams :
- To have clear visibility on what has been released and when
- To get more organized around an ongoing release, tracking its progress and its dependencies, and making sure that no item has been forgotten or missed.
- To share visibility on the next releases
Again, it’s not necessarily about dates, but about organizing the product timeline into meaningful and clear increments that will help navigate the product evolution across time.
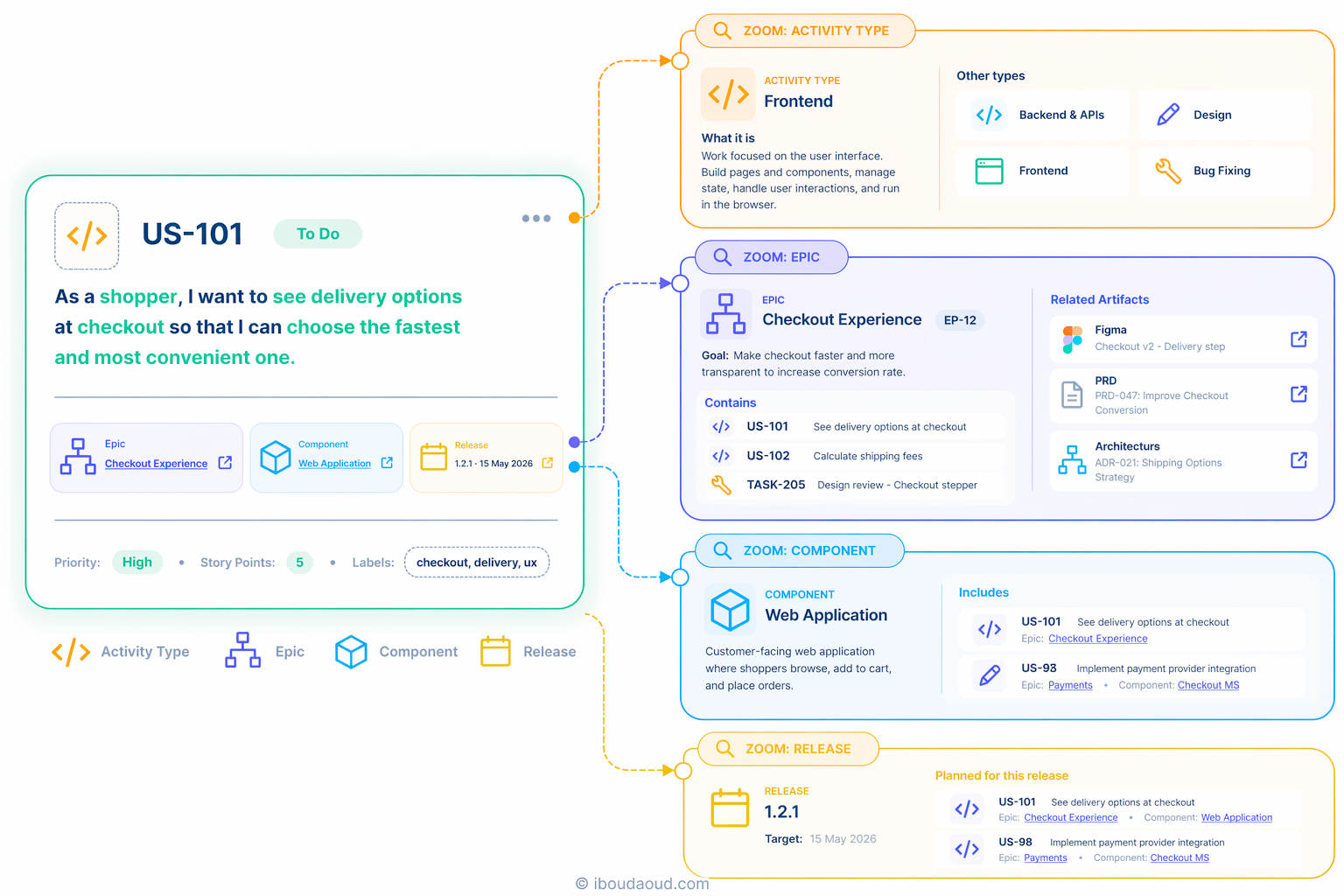
One of the options in structuring releases is to use semantic versioning (SemVer) that will identify each version a X.Y.Z number where :
- X is mainly incremented when there is a major release
- Y is incremented when there is a new feature or increment
- Z is incremented for bug fixes, patches or minor iterations around features
The use of versions and releases not only improved backlog visibility at the product level, but it’s also helpful to track increments at the feature (epic) level and at the component level.
6. Tags … one more dimension for your flexibility
The 5 dimensions listed are a great way to structure a product backlog but sometimes you need an extra layer that is specific to your context and your organization, let’s say for example, you want to link your backlog items to your different business streams to have a clear idea on the wok involved in each stream. This is luckily possible through tags.
Tags are an excellent way to add an extra context layer to your work backlog while maintaining the 5D Structure.
There are no strict rules in using tags. You can design a tags system that is aligned with your needs and organization and you can link as many as you want to your backlog items.
It’s a bonus layer, you can use it if it makes sense and you can ignore it if the 5D system covers all your needs.
What about the "Who"?
Shouldn't the assignee (the "who") be part of the backlog structure model?
Of course, every ticket will have an assignee. That's not the question. The question is whether individual ownership should be part of the structural model itself, and I don't think it should.
"Who" is the most volatile piece of information in a system: people move, priorities shift, teams reorganize. Building structure around people makes that structure fragile. More fundamentally, the five dimensions describe the work itself, not the state of the work at a given moment. Ownership is a state.
That said, the "Where" dimension already carries implicit ownership at a more stable and useful level. A component maps to a team or a service owner far more durably than an individual assignee ever will. If your components are well-defined, you rarely need to ask who owns a piece of work. The architecture answers that question for you.
How does this work in practice?
To see how this works in practice, let’s imagine that you’re building a trip planning app. How would you proceed step by step to structure your backlog?
List the product components or domains
The first step would be to list and create product components in your preferred backlog management tool.
For our use case, the list would be for example :
- Webapp
- Mobile app
- Middleware
- Admin backoffice
- AI agent (as your product also has a WhatsApp agent that users can use to interact with the product)
List the types of activities the team will handle
According to your team composition, you may have identified the following activities:
- Design: all the activities related to ux and ui design
- DevOps: all activities related to infrastructure management, pipelines, etc
- Technical design: all activities related to architecture, technical design, or technical investigations
- Frontend: all activities related to frontedn software development
- Backend: all activities related to backend software development
- Bug: all activities related to bug fixing
- …
Creating the high-level structure
Once this is done, and before starting to create individual tasks, it’s important to have the high-level structure around the backlog, which is creating epics.
You’ll be creating two types of epics :
- Features with direct value to end users: like account management, payment flow, etc
- Enablers and capabilities for the product: like SEO, RGPD compliance, security, performance, and so on.
Creating your backlog items and linking them to the structure
Now you’re ready to create individual user stories and tasks. Each user story will :
- Have its activity type
- Be linked to its component
- Be linked to its epic (or high-level goal)
Creating the timeline
The final step will be to create the timeline, which is structuring your backlog into incremental versions or releases. Each version or release will contain a bucket of tickets that are related to specific components.
A backlog is not a list; it’s a system
A backlog is not just a place where work is stored. It's a system that reflects how a team understands its product, makes decisions, and moves forward.
This matters more than ever right now.
As AI agents become part of how products are built (generating tasks, breaking down features, executing work autonomously), the backlog stops being just a coordination tool for humans. It becomes an interface that both humans and agents need to read, interpret, and act on reliably.
Structure isn't just about team alignment anymore. It's about making your product understandable to systems that don't ask clarifying questions.
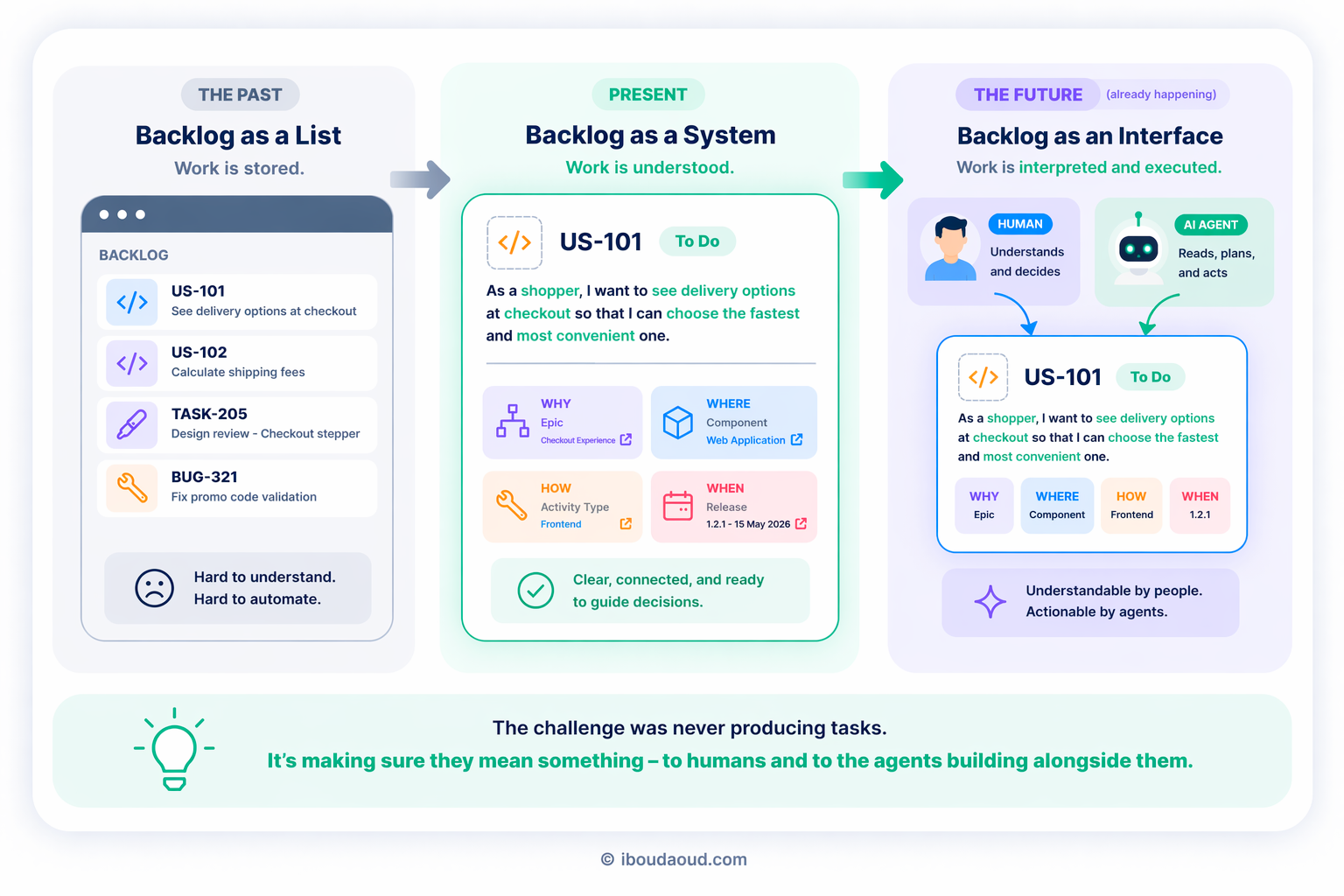
The teams that figure this out early won't just have cleaner backlogs. They'll have a meaningful operational advantage as AI becomes a bigger part of how products get built.
The challenge was never producing tasks. It's making sure they mean something - to the people building the product, and increasingly, to the agents working alongside them.